-
NextJS + k8s 프로덕션 환경에서 OOMKilled 현상클라우드 2023. 10. 25. 10:18반응형
🚫 문제발생
현재 관리 중인 서비스는 EKS를 통해 배포 중이고 NextJS를 쓰는 Front 역시 해당 클러스터에 배포되어있다. 정식 배포 이후 얼마 뒤부터 주기적으로 서버가 다운됐다가 복구된다는 CS요청을 받았다. 현재 상태를 확인한 결과 아래 사진처럼 Front 배포 Pod이 수없이 Evicted, 말 그대로 클러스터에서 추방 당했다. 해당 Pod의 로그를 보니 OOMKilled 상태였고 빠른 조치가 필요했다.
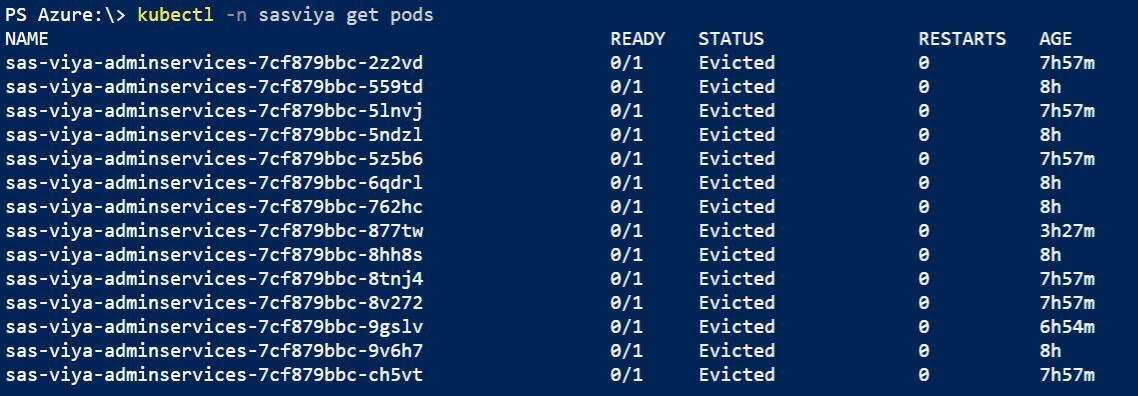
출처: https://github.com/sassoftware/sas-container-recipes/issues/12 처음엔 당연히 코드 상의 실수로 Memory Leak이 발생해서 해당 문제가 생겼다고 생각했다. 그런데 확인해보니 같은 스펙의 클러스터와 같은 빌드 버전을 사용 중인 Dev, Staging에서는 해당 문제가 전혀 발생하지 않고 있었다. 트래픽에 대한 스트레스 테스트를 진행한 적이 없기에 트래픽 문제일 것이라 가정하고 원인 파악을 시작했다.
우선 현재 얼만큼의 트래픽이 몰릴 때 서버에 이상이 생기는지 모니터링이 필요했기에 CloudWatch를 통해 이를 모니터링하고자 했다. 일반 인스턴스처럼 CloudWatch에서 지표 확인만 하면 된다고 생각했으나 EKS의 경우 Log와 Metric 지표를 수집하려면 직접 세팅이 필요하다.
⚙️ EKS에서 Container Insights 설정
모니터링을 CloudWatch Console에서 확인할 수도 있지만 이를 Slack 등의 SNS를 통해 이벤트를 뿌려주면 더욱 실시간으로 모니터링이 용이해진다. 여기서는 서버의 부하로 인한 Restart를 빠르게 확인하고 그때의 메모리 사용량을 함께 파악하기 위해 Restart 위주로 트리거를 걸었다.
⚙️ Amazon Chatbot으로 Slack 경보 설정
모니터링 세팅 이후 트래픽으로 인한 메모리 부하의 문제라면 Pod의 오토스케일링으로 해결이 가능할 것이라 생각했다. 다행히 우리 프로젝트에서는 Helm Chart를 쓰고 있었기에 오토스케일링 설정이라면 간단했다. 추가로 겸사겸사 무중단 배포의 다운타임을 최소화 시키는 Graceful Shutdown 세팅도 함께 진행했다.
최종적으로 발생한 이슈의 원인은 시스템의 파일 다운로드 로직에 있었다. 레거시 코드 중 특정 페이지의 첨부파일 다운로드 시 이를 브라우저에서 받지 않고 NextJS의 API를 통해 다운로드를 요청하는 로직이 문제 발생의 원인이었다. 일반적으로 NextJS에서는 Next API를 통해서 주고 받는 Response의 limit을 4mb로 잡고 있다. 4mb 이상의 파일을 다운로드 시 NextJS에서 당연히 부하가 발생하고 이는 결국 클러스터의 메모리를 잡아먹기 때문에 용량이 큰 파일을 다운로드 시 OOMKilled가 일어날 수 밖에 없다.
발생 원인은 코드에 있었지만 덕분에 미뤄뒀던 인프라 세팅을 제대로 수정했다.
반응형'클라우드' 카테고리의 다른 글
⚙️ Amazon Chatbot으로 Slack 경보 설정 (1) 2023.11.02 ⚙️ EKS에서 Container Insights 설정 (0) 2023.11.02 PaaS-TA #3 Paas-TA PlayPark 설정(1014) (0) 2020.10.14 Paas-Ta #2 환경설정(1007) (0) 2020.10.07 PaaS-TA #1 환경설정(0923) (0) 2020.09.23