-
#6. 데이터 전처리인공지능/케라스 창시자에게 배우는 딥러닝 2021. 2. 14. 21:02반응형

위의 사진은 데이터 사이언티스트가 데이터를 수집하여 모델을 도출해내기까지 어떤 단계에서 얼만큼의 시간이 사용되는지를 보여준다. 이를 보면 절반 이상의 시간이 데이터를 전처리하는데 사용된다. 그만큼 데이터의 전처리는 모델의 성능에 가장 직결되는 문제이고 그만큼 중요하다. 전처리의 목적은 주어진 데이터를 신경망에 적용하기 용이하도록 변환하는 것이다.

신경망의 입력과 타깃은 컴퓨터의 실수 표현 방식인 부동 소수 데이터로 이루어진 데이터여야 한다. 이를 위해 이미지, 텍스트 등의 모든 데이터 형태는 텐서로 변환이 필요하다. 이 단계를 데이터 벡터화(Data Vectorization)라고 한다. 위의 사진처럼 원-핫 인코딩(One-hot Encoding) 역시 데이터 벡터화의 일종이라 할 수 있다.
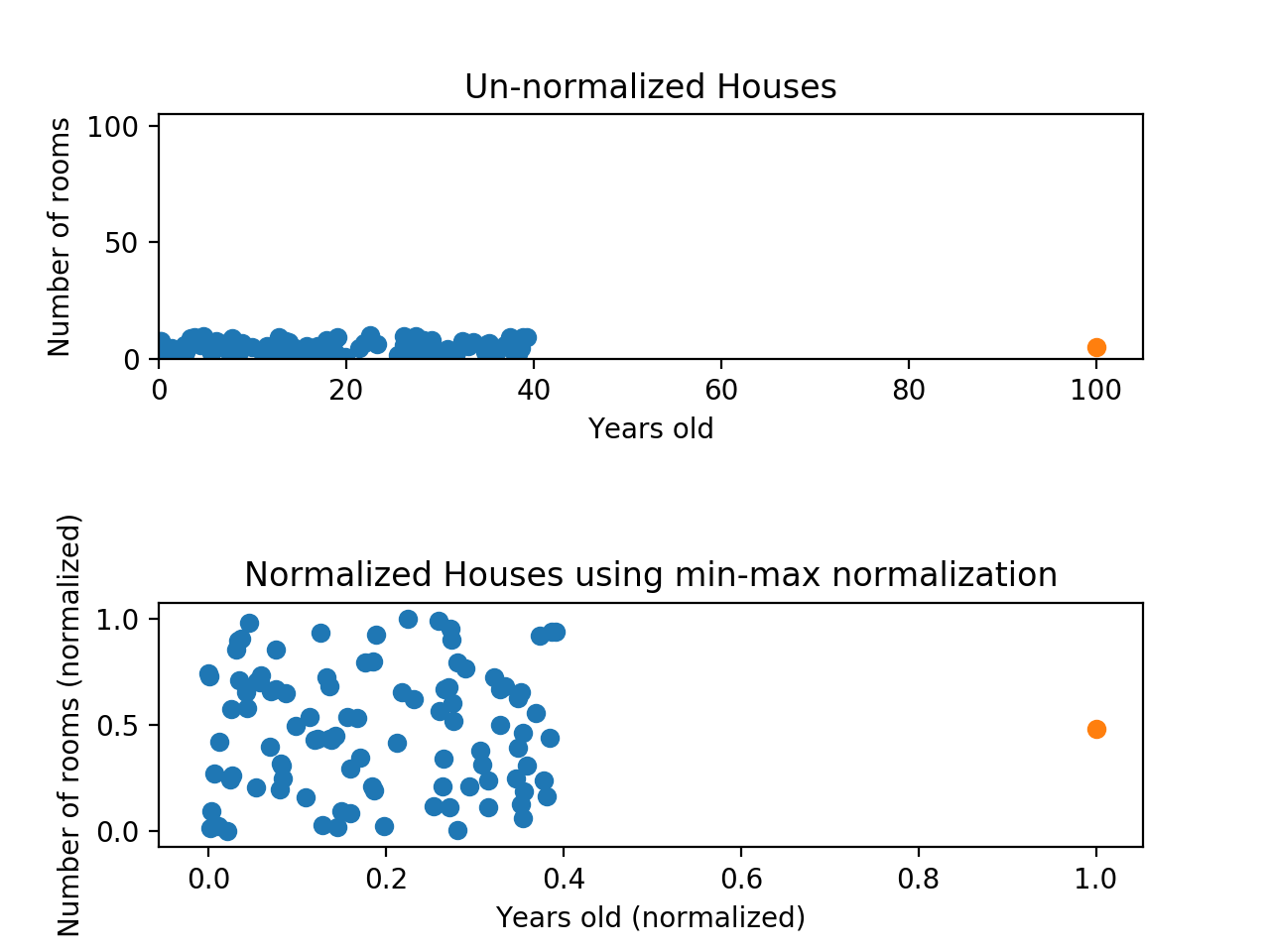
입력 데이터가 신경망 내부에서 원활히 활용되기 위해서는 데이터가 균일해야 한다. 데이터의 값이 균일하지 않거나 데이터의 크기가 클 경우 업데이트 해야할 값이 커져 네트워크가 수렴하는 것을 방해한다. 따라서 데이터를 평균이 0이고 표준편차가 1인 데이터로 만드는 것은 더 좋은 모델을 위해 매우 긍정적인 역할을 한다. 넘파이 배열에서 정규화를 하는 방법은 다음과 같다.
x -= x.mean(axis=0) # 데이터의 모든 값에 데이터의 평균을 뺀다. x /= x.std(axis=0) # 위의 모든 값에 데이터의 표준편차를 나눈다.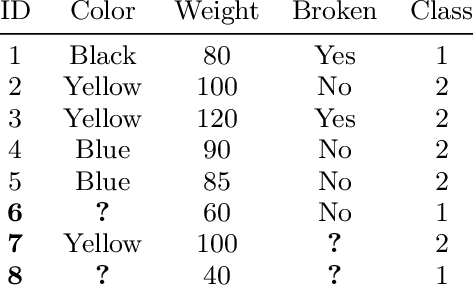
데이터에 결측치, 즉 누락된 값이 존재하면 모델의 학습에 장애가 발생할 수 있다. 이를 방지하기 위해 데이터의 결측치를 미리 확인하는 것은 중요하다. 데이터의 결측치를 확인하면 이 데이터를 제외할지 혹은 채워넣을지를 결정해야한다. 일반적으로 데이터의 양이 충분하지 않을 경우 데이터를 제거하는 것은 그다지 효율적인 방법이 아니다. 따라서 데이터의 중간값 혹은 평균값, 0 등으로 데이터를 채워넣는 방법이 필요하다.

마지막으로 볼 방법은 특성 공학이다. 이 특성 공학은 데이터를 미리 좀 더 학습이 수월한 데이터로 미리 변환시켜준다. 예를 들어 시계의 시간을 읽기 위한 그림이 존재할 경우 시침과 분침의 끝을 좌표 데이터로 변환할 경우 신경망에 훨씬 간단한 방법으로 데이터를 적용시킬 수 있다. 이러한 특성 공학은 신경망이 자동으로 특성을 추출해주기에 반드시 필요하지는 않지만 때에 따라 더 나은 모델을 더 적은 데이터로 만들어 줄 수 있다.
반응형'인공지능 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
#8. 합성곱 신경망(Convolutional neural network, CNN) (0) 2021.02.22 #7. 과대적합과 과소적합 (0) 2021.02.14 #5. 일반화된 모델을 위한 데이터 분할 (0) 2021.02.14 #4. 머신러닝의 분류 (0) 2021.02.14 #3. 신경망의 구성요소 (0) 2021.02.07